カッパ係数 (自由回答,インタビューなどの分類の信頼性,一致度)
ファイルは,www.mizumot.com/stats/kappa.xlsにあるので計算式を確認してください。
【例】
3クラス(80人)で中間テスト2週間前から,生徒に学習日記をつけるように指示しました。
その日記の自由記述で自宅での学習に関する内容は,以下の3つに分類できると考えられました。
A − テスト以外の目的のための学習
B − どちらにも当てはまらない
C − テストのための学習
この分類を確認するために,25%*の生徒(n = 20)の日記をランダムに選択し,
この分類の一致度を確認するための信頼性を計算するにはどうしたら良いでしょうか?
以下の形でデータを入力します。
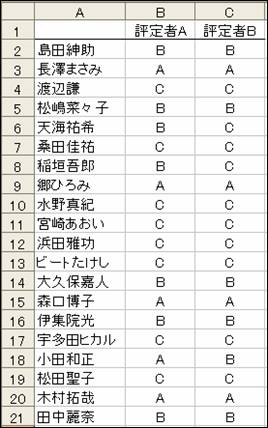
このような信頼性は,単純に分類を行った2人の分類の一致度を報告する場合も多いですが,
Cohen’s Kappa(カッパ係数)と呼ばれるものを計算することもできます。
カッパ係数は,カイ二乗の考え方と同じく,実測値と期待値を比べることによって算出されます。
カッパ係数の値(k)の値は−1 ≦ k ≦ 1 となり,数値が1に近いほど評定者の分類は一致していることを表し,
k=1になった場合は完全な一致となります。
kが0.81〜1.00の間にあればほぼ完全な一致、0.61〜0.80の間にあれば実質的に一致しているとみなされます。
【コーディングの一致度を確認するためのサンプリングは全体の10%でOK】
*Loewen,
S., & Philp, J.(2006). Recasts in the adult L2 classroom: Characteristics,
explicitness, and effectiveness.
Modern Language Journal, 90, 536-556.では以下のような記述がありました。
“
acceptable
subsample to use for interrater reliability coding.”
参考URL: http://www.temple.edu/mmc/reliability/
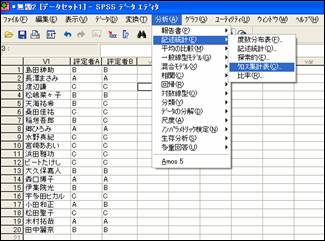
SPSSを使って分析する
SPSSでは「分析」⇒「記述統計」→「クロス集計表」を選ぶ。
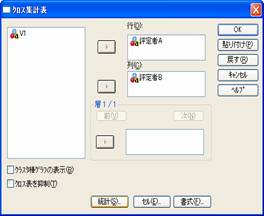
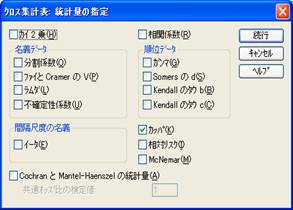
評定者AとBをそれぞれ行と列に移動して,「統計」をクリックして,右のボックスの中の「カッパ」をチェックしておいて「続行」をクリックします。
![]()
![]()
![]()

以下のような結果が出力されます。
![]()
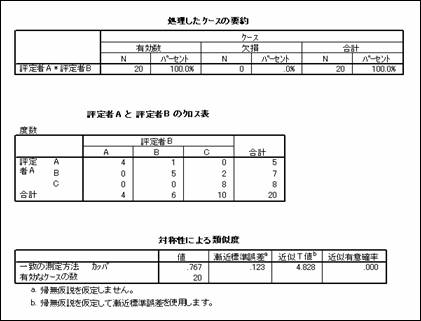
【 結果の報告 】
生徒の学習日記の自由記述の3つの分類がどれだけ信頼性のあるものかを検討するために,
専門家2人が25%の生徒(n = 20)の日記をランダムに選択し,
カッパ係数を求めた。その結果,k = .77という実質的に一致しているとみなされる高いカッパ係数が確認された。
EXCELを使って分析する
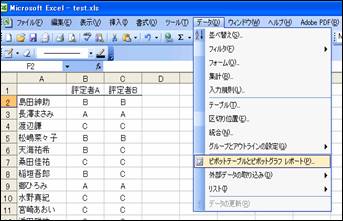
「データ」⇒「ピボットテーブルとピボットグラフ レポート」を選ぶ。
ピボットテーブルを使うと,集計表を簡単に作成することができます。
![]()
![]()
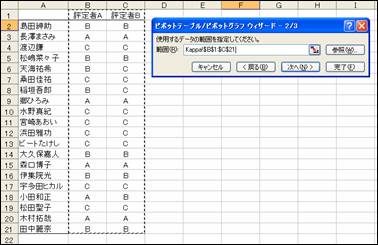
以下のように範囲を指定して「次へ」をクリック。
クロス集計表を作るために,以下のようにデータを移動する。
「評定者B」をここにドラッグ&ドロップする
「評定者A」をここにドラッグ&ドロップする 「評定者A」をここにドラッグ&ドロップする
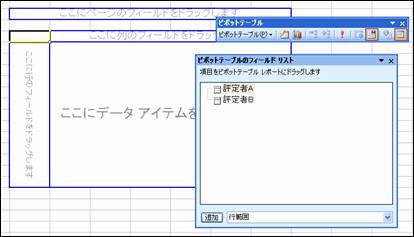
以下のようになれば集計成功です。続けて,表の範囲を選択して,「コピー」[1]する。
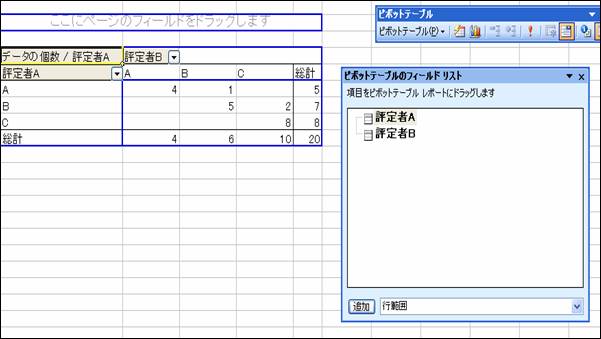
ピボットテーブルの下あたりの空いているセルにコピーした表を貼りつけます。
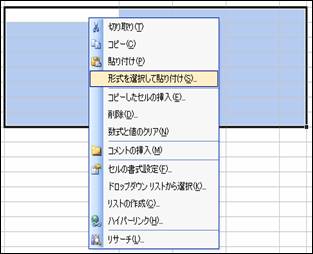
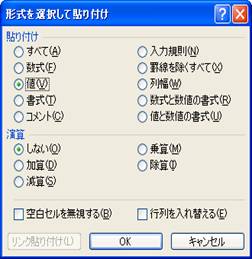
そのままだと,ピボットテーブルの形式が残ってしまうので,
右クリックして,「形式を選択して貼り付け」を選びます。「値」をチェックして「OK」おクリックします。
![]()
![]()
以下のように表を貼り付けることができたら,
データが入っているセルに何も入力されていない状態にします(黄色に塗りつぶしている部分です)。
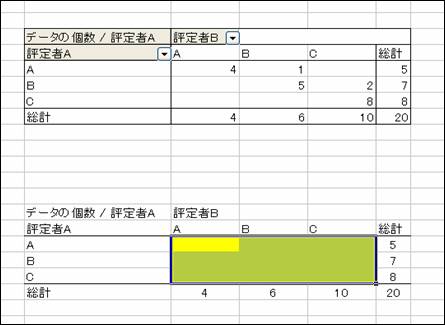
以下のように期待値を計算する式を入力します。
(行の合計×列の合計)÷すべての合計という簡単な式になっていることを確認してください。
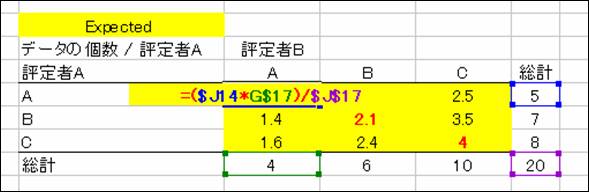
後にカッパ係数を計算する式を以下のように入力します。
計算式はExcelファイルのセルを確認してください。

結果が計算されました。
![]()
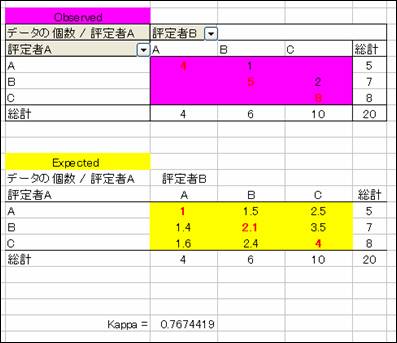
【 結果の報告 】
生徒の学習日記の自由記述の3つの分類がどれだけ信頼性のあるものかを検討するために,
専門家2人が25%の生徒(n = 20)の日記をランダムに選択し,
カッパ係数を求めた。その結果,k = .77という実質的に一致しているとみなされる高いカッパ係数が確認された。